
はじめに
PCやNASに格納されているファイルを検索したい時にWindows純正の検索方法では時間がかかり、ファイルの中身まで検索することはできません。なので今回はテキストファイルやOffice系のファイルにPDFまで幅広いフォーマットに対応した全文検索システムをLLMを組み合わせて作ってみました。
ファイルのクロールと全文検索システムへの登録
ファイルを検索するためにはまず検索システムに対してデータを登録しなければなりません、なのでNorconex File System Crawlerを利用してデータをクロールします。
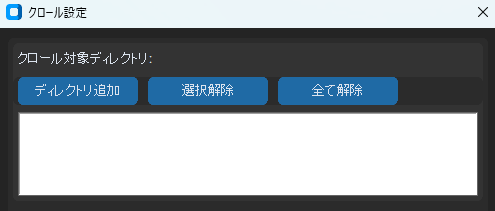
データのクロールはコマンドから行うことができますが、使いやすいようにGUIで操作できるようにしました、UIはPythonのtkinterをメインで使っています。
ここでクロールしたいディレクトリを選択してクロールを開始します。
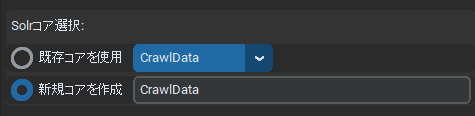
またクロールが終了するタイミングでApache Solrのコアに登録を行います。
Apache Solrは全文検索システムで、これに対して文書データなどを登録することで検索をかけることが可能になります。
このアプリケーションではSolrはJava 21を使用してSolrサーバーを起動します。次にデータを格納する「コア」というものを作成する必要があり、これをGUI上から名前を入力して作成することができるようになっています。
一度作成したコアはSolrサーバーを再起動しても既存コアに残っているので毎回クロールする必要はありません。

Solrコアの選択を行うとクロール開始ボタンが押せるようになり、このボタンを押すことでクロールが可能になります。
クロールが開始されると事前に設定しておいた設定ファイルに応じてエクセルやワードファイルなどが内容を抽出してSolrコアへ登録されていきます。またそれと並行してPDFは画像埋め込みにも対応させているため、PDFのみ別途切り分けて処理を行い、PDF1ページごとを画像化して文字抽出を行い、統合したものをクロールさせています。またこの時、検索時に元のPDFファイルパスが正しく参照できるようにパス情報を含むテキストファイルを生成しています。
そして全てのファイルのクロールが終わると検索ができるようになります。
LLMを活用して検索をしてみる
LLMはアプリケーション起動時にSolrの起動と並行してllamaサーバーを起動してDeepSeekR1の日本語蒸留モデルをCudaに対応させる形でロードしています。
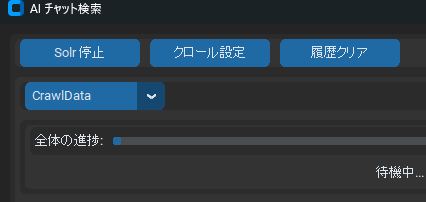
まずはメインの画面でSolrコアの選択を行います。今回は「Data」という名前のコアを作成してそこにデータをクロールしたのでこれを選択します。
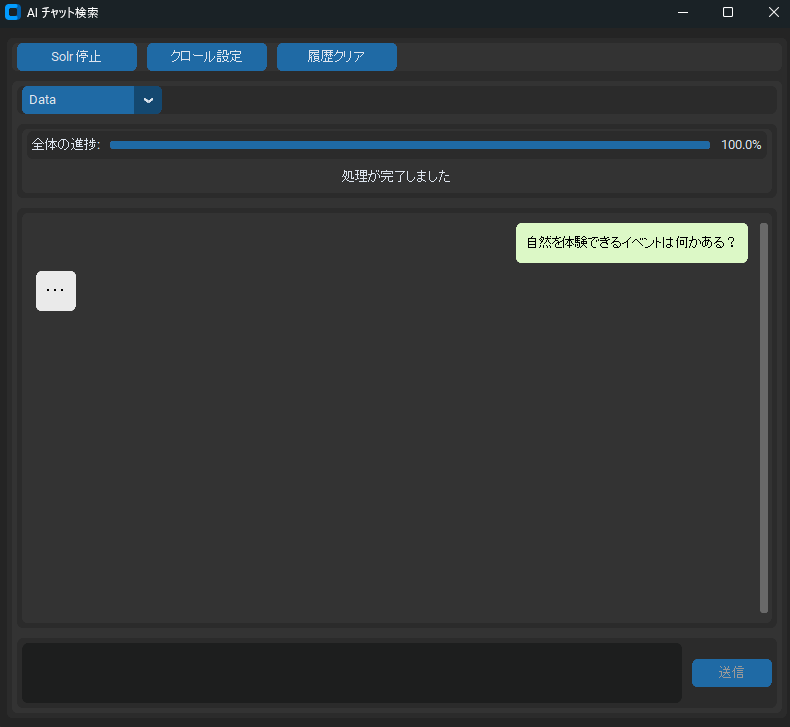
次にメインの画面下部のチャット入力欄に質問したい文言を入れて送信します。
そうするとチャット画面に「…」の表示がでて裏で検索と回答が行われます。
この時、裏ではユーザーの入力した文字からキーワードを抽出してSolrで検索を行い、返ってきた結果の関連度の高い上位5つのデータをLLMに渡しています。

そして検索結果が渡されたLLMはその中からユーザーの求めるデータを集めて回答を生成します。
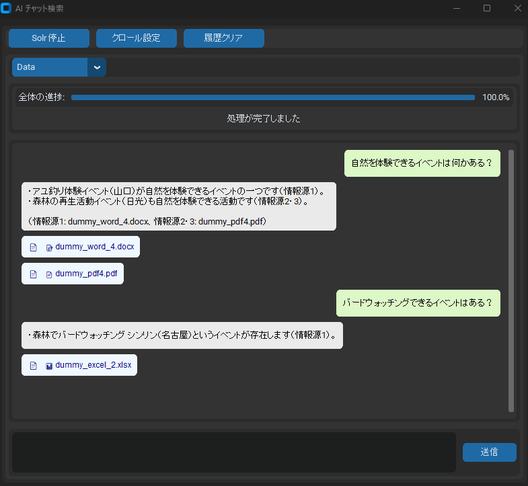
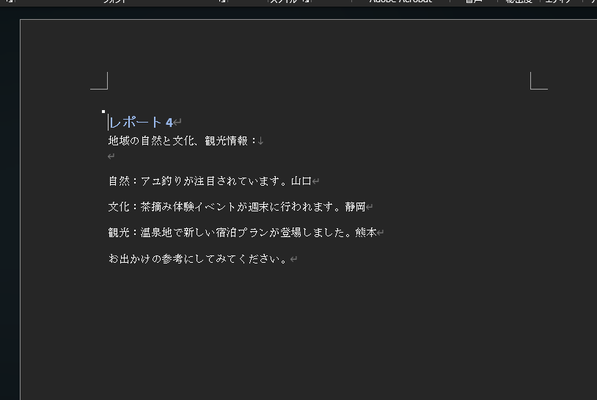
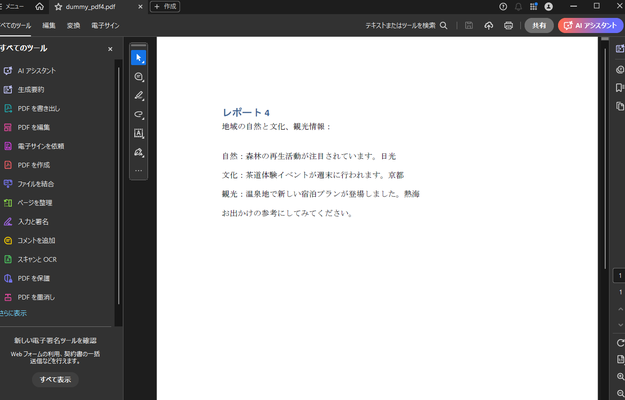
それぞれの参考資料の元データの中身は以下の通りです。

回答が生成されるとチャットウィンドウに回答と、それに関連のあるファイルが添付されたバブルが表示されます。
今回の例ではイベントと開催地のデータが格納されているエクセルファイルをクロールしていて、「春祭りの開催地はどこだっけ」と質問しました。そうするとLLMの回答は「春祭りの開催地は札幌です。」と資料の内容を読んで回答を行ってくれています。
回答の下に添付されている資料はクリックをすることで元のファイルを開くことが可能となっています。
また添付資料は.xlsxや.docxなど元のファイル形式のまま表示が行われます。これはOCRを行うPDFにも対応しており、文字抽出を行ったデータの登録を行うとPDFそのものの登録ではなくPDFの文字抽出を行ったテキストファイルを登録している扱いになるので参考資料には抽出したテキストファイルが表示されてしまう問題がありましたが、調整を行いOCR済PDFも元のファイルが開けるような仕組みになっています。
ファイルクロールとRAG(検索拡張生成)の時系列フロー
ファイルクロールのフロー
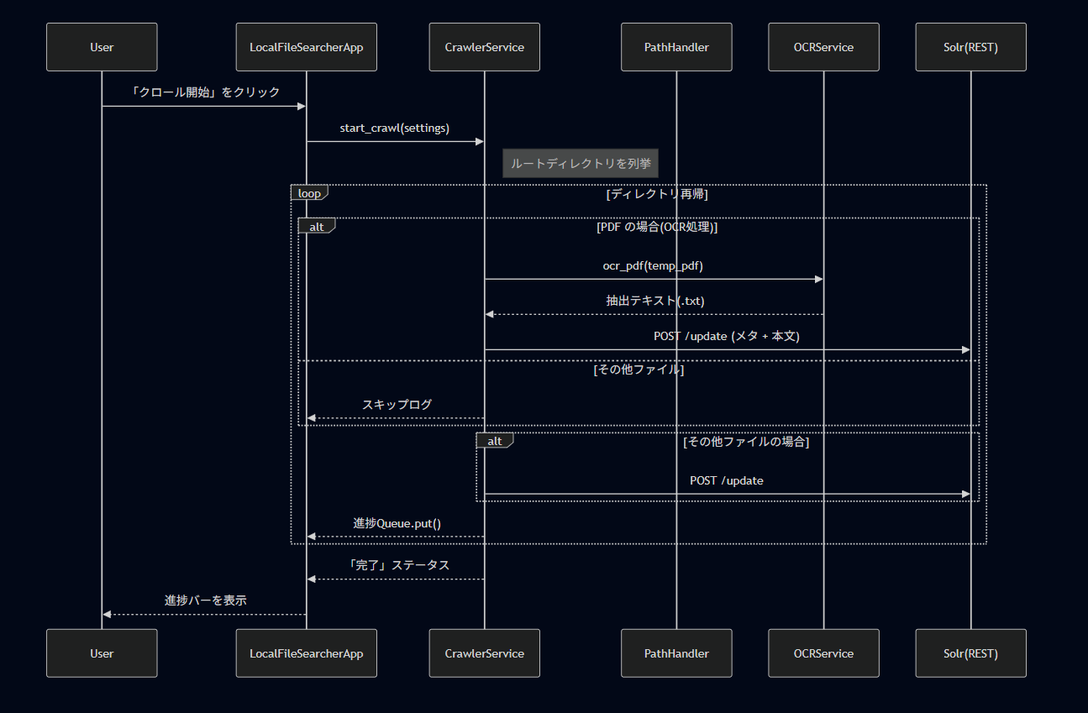
ファイルのクロールは主にPDFファイルとOffice系その他ファイルとで分けて処理を行っています。
実はPDFやOffice含むその他テキストファイルはそのままクロールを行ってSolrに対して登録ができるのですが、PDFのみ処理を分けているのには理由があり、今回クロールするPDFの中には画像が埋め込まれてあるだけのPDFが存在しており別途文字の抽出が必要だと判断したため処理を分けています。
PDFのOCRには時間がかかるので、まずクロールが始まると指定されたフォルダ以下のPDFを全て探してOCRを行います。これは非同期処理で行っているのでそれと並行してその他ファイルをクロールします。全てのファイルのクロールが終了してPDFのOCRとSolrへの登録が終わった時点でユーザーが見ることのできる進捗バーが100%表示になり、完了を通知します。
RAGのフロー
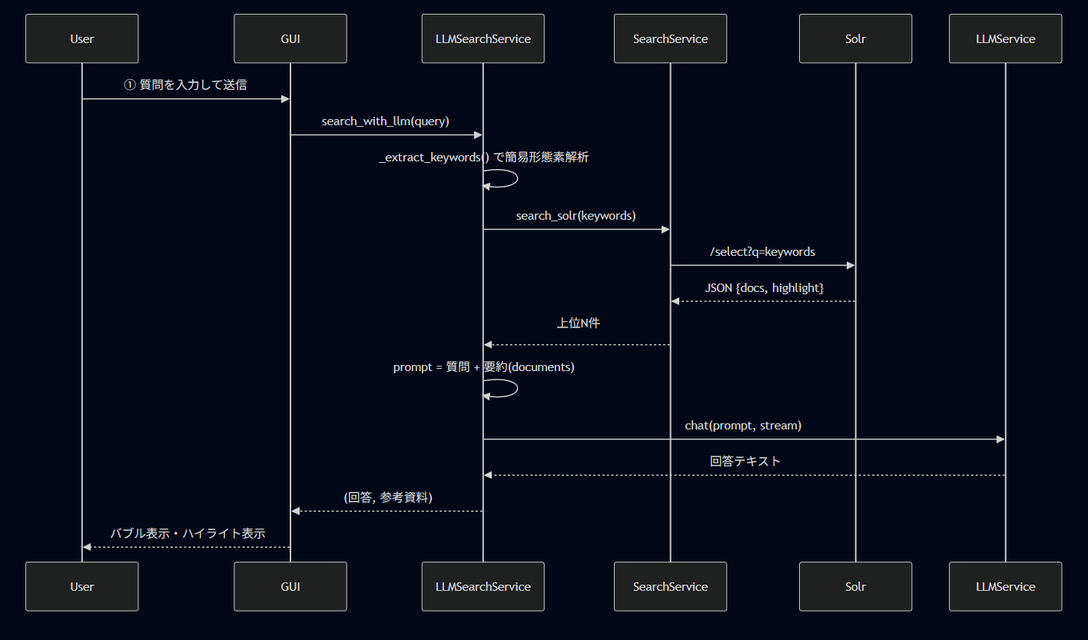
まずユーザーが質問を送信するとその中から重要なワードを抜き取りSolrに対して検索をかけます。その後上位N件のデータが返ってくるので、プロンプトで質問にそのデータを加えてLLMに送信します。そうすると回答が返ってくるので、使用したデータを参考資料として添付しつつバブルチャットに回答を表示する流れとなっています。
まとめ
ただの全文検索システムから、実際にファイルの中身を読んでそれに沿った回答を行ってくれる検索システムになりました。
これまではファイルのタイトルで絞るしか検索ができなかったものが、これを使うとそこそこ高速で知りたいことがきちんと検索できるようになります。
また、SolrもLLMもローカルでサーバーを動かすので外部にファイルが送信されることもなく機密情報を含むファイルをクロールして検索することも可能となっています。
ただし課題もあり、現状では1つのPCに対して1つアプリを立ち上げる必要があり、どこかのマシンをホストにしてそこに他の人がアクセスして使うことは想定されていません。
またLLMを使用するのにNVIDIA製のGPUでVRAMが12GB以上はないと動作が厳しいなどハードウェアの性能を要求されます。
更にローカルLLMは大手のLLMに比べて性能がどうしても劣ってしまい、ハルシネーションが起こりうる可能性はあるので回答をうのみにすることはできないという問題があります。
しかしそれらを加味してもローカルで完結するLLM対話型RAG検索システムは便利なものだと実際に使って見て感じました。

上記ブログの内容に少しでも興味がありましたら、お気軽にご連絡ください。
弊社のエンジニアがフレンドリーに対応させていただきます。
