
はじめに
近年、ジェスチャーや音声などを使った「自然なユーザーインターフェース(NUI)」への関心が高まっています。
特にXR(拡張現実)やメタバースなどの分野では、より直感的でハンズフリーな操作が求められる場面が増えています。
今回の検証では、Googleが提供するAIライブラリ「MediaPipe」と、インタラクティブアプリ開発でおなじみの「Unity」を組み合わせて、普通のWebカメラだけでUIを手のジェスチャーで操作する体験を再現してみました。
高価なセンサーや特別な機器は一切不要で、PCひとつで動かせるのがポイントです。

使用した技術
今回の検証で使用した主な技術は以下の通りです。
- Unity ゲーム開発やXRアプリケーションに広く使われているリアルタイムエンジン。UIの構築や外部ライブラリとの統合がしやすく、プロトタイピングにも適しています。
- MediaPipe Googleが開発した、手や顔などの動きをリアルタイムで検出・分類できるオープンソースのAIライブラリ。軽量かつ高速に動作し、PCやモバイル端末でも実用的です。
-
MediaPipeUnityPlugin(非公式プラグイン) MediaPipeのC++ベースの処理をUnity上で簡単に呼び出せるようにしたUnity向けのプラグイン。今回はこのプラグインを使って、手のランドマーク検出とジェスチャー認識を行いました。
実装したデモ
今回のデモは大きく2つのパートに分かれています。
手のランドマークとジェスチャー
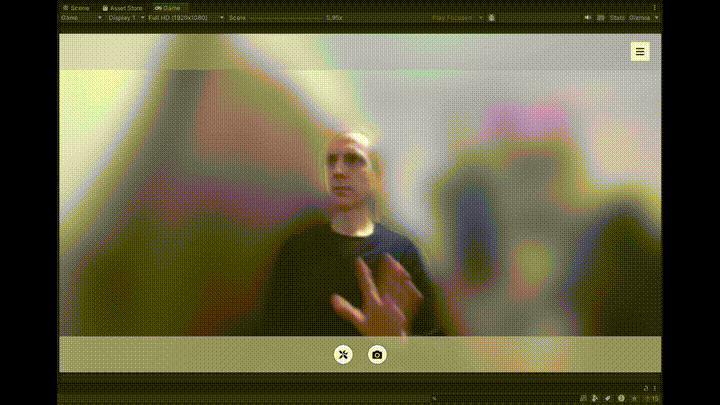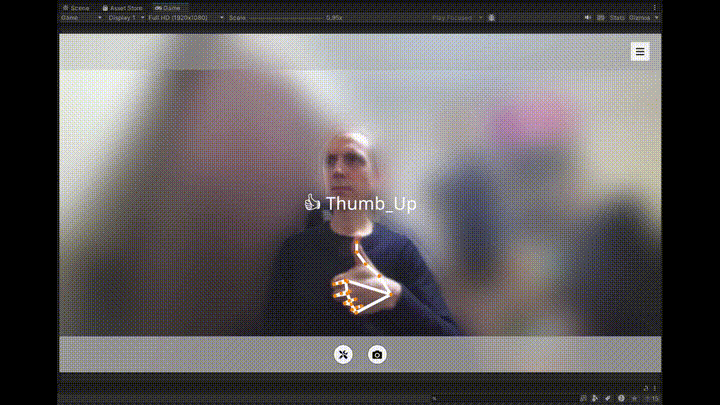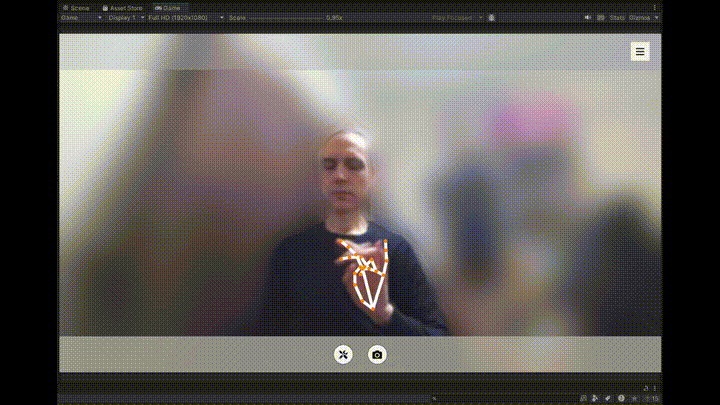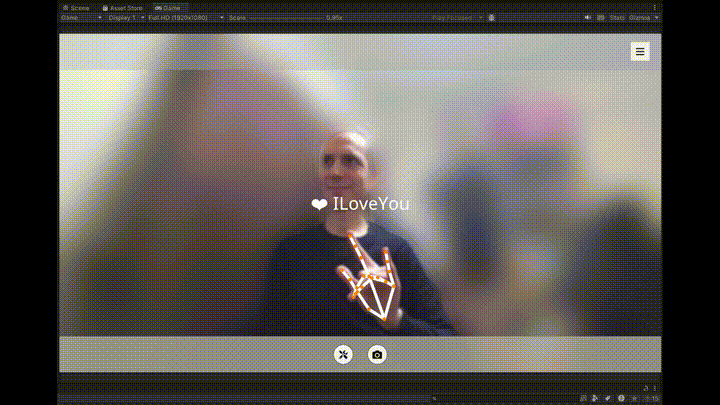
1つ目は、MediaPipeを使ってWebカメラの映像から手のランドマークとジェスチャーをリアルタイムで検出・表示する部分です。
認識されたジェスチャー(✋、✊、☝️など)は、画面上にアイコンと共にテキストで表示され、視覚的なフィードバックが得られるようになっています。
| ジェスチャー名 | 表示されるアイコン |
| Closed_Fist | ✊ |
| Open_Palm | ✋ |
| Pointing_Up | ☝️ |
| Thumb_Up | 👍 |
| Thumb_Down | 👎 |
| Victory | ✌ |
| ILoveYou | 🤟 |
UIジェスチャー操作
2つ目は、検出した情報を使って、UnityのUIとインタラクションを行う部分です。
ここでは、指の先端(landmark 8)の位置をポインターとして扱い、UIボタンの上に指が乗った状態で、特定の動き(前方への動き)を検出することでボタンを押すことができます。
一方、スライダーの操作には「握りこぶし(✊)」ジェスチャーが必要で、つかんだ状態で左右に動かすと値が調整されます。
このように、MediaPipeの出力を活用して、簡単なUIを直感的に操作できるような体験をUnity上で再現しました。
実装の流れ
今回のデモは、MediaPipeUnityPluginのサンプルプロジェクトをベースに構築し、最新バージョンで追加された「ハンドジェスチャー認識機能」を活用して実装を進めました。以下はその主なステップです。
1. Unityプロジェクトへのプラグイン導入 :
MediaPipeUnityPluginをUnityにインポートします。最新版では gesture_recognizer モデルが新たに追加されており、これを使うことでピースサインや握りこぶしなどのジェスチャーをリアルタイムで分類できるようになっています。
2. 既存のサンプルシーン(HandLandmarkDetection)の活用:
プラグインに含まれるサンプルシーン「Hand Landmark Detection」をベースに使用しました。このシーンではすでに、Webカメラからの入力映像に対して手の関節(ランドマーク)をリアルタイムで検出できるようになっており、正しく動作しているかをすぐに確認できます。
検出処理の主な流れは以下の通りです:
-
// モデルの読み込み -
yield return AssetLoader.PrepareAssetAsync(config.ModelPath); -
-
// HandLandmarkerの初期化 -
var options = config.GetHandLandmarkerOptions( -
config.RunningMode == Tasks.Vision.Core.RunningMode.LIVE_STREAM ? OnHandLandmarkDetectionOutput : null -
); -
-
taskApi = HandLandmarker.CreateFromOptions(options, GpuManager.GpuResources);
この taskApi は毎フレーム画像を受け取り、ランドマークの検出処理を行います:
-
taskApi.DetectAsync(image, GetCurrentTimestampMillisec(), imageProcessingOptions);
検出された手のランドマーク情報は、次のようなコールバック関数で受け取って処理します:
-
private void OnHandLandmarkDetectionOutput(HandLandmarkerResult result, Image image, long timestamp) -
{ -
// 検出結果に応じた表示や処理をここで行う -
}
この時点で、指の位置や手の向きなどをリアルタイムで取得することができ、視覚的に確認することも可能です。
3. ジェスチャー認識の追加実装:
このベースに対して、ジェスチャー認識機能を追加しました。
HandLandmarker の例と同様に、モデルの読み込み、初期化、コールバック関数の指定、そしてフレームごとの処理という流れで構成されています。
まず、モデルファイル「gesture_recognizer.bytes」は以下のように読み込まれます。ファイルはパッケージ内に含まれており、「AssetLoader.PrepareAssetAsync(...)」 により読み込みます。
-
yield return AssetLoader.PrepareAssetAsync("gesture_recognizer.bytes"); -
var gestureRecognizerOptions = new GestureRecognizerOptions( -
baseOptions: new Tasks.Core.BaseOptions(Tasks.Core.BaseOptions.Delegate.CPU, modelAssetPath: "gesture_recognizer.bytes"), -
runningMode: Tasks.Vision.Core.RunningMode.LIVE_STREAM, -
resultCallback: OnGestureRecognitionOutput -
); -
var gestureRecognizer = GestureRecognizer.CreateFromOptions(gestureRecognizerOptions, GpuManager.GpuResources);
その後、毎フレームの画像に対して以下のようにジェスチャー認識を実行します。
-
gestureRecognizer.RecognizeAsync(imageForGesture, GetCurrentTimestampMillisec(), imageProcessingOptions);
認識結果は、コールバック関数 OnGestureRecognitionOutput で受け取って処理します。
-
private void OnGestureRecognitionOutput(GestureRecognizerResult gestureResult, Image image, long timestamp) -
{ -
// 検出結果に応じた表示や処理をここで行う -
}
4. UI操作への応用:
検出された情報を使って、簡単なUIジェスチャー操作を実装しました。具体的には以下の2点です:
- UIボタンの押下:指先(landmark 8)の位置を画面上のポインターとして扱い、ボタンの上にあるときに指を前方に動かすことで押下判定を行います。
- スライダーの操作:ジェスチャーが「Closed_Fist」(握りこぶし)の間だけ、手のX座標に応じてスライダーの値を動的に変更します。ジェスチャー認識の活用例として実用的です。
結果と考察
今回のデモを通じて、MediaPipeを使ったハンドジェスチャー認識が非常に高速かつリアルタイムで動作することを確認できました。
レスポンスも良好で、2D画面上のUI操作に対して十分な精度を持っていると感じました。
ただし、MediaPipeのランドマーク座標は相対的な3D情報であり、実際の空間的な深度情報とは異なります。
そのため、Z軸方向の動きや空間的な配置を正確に把握するには限界があり、3D空間上でのインターフェース操作にはやや不向きな面もあります。
以下に、MediaPipeと深度センサーカメラの違いを簡単にまとめます。
| 特徴項目 | MediaPipe(Webカメラ) | 深度センサー付きカメラ(例:Kinect) |
| 必要な機材 | Webカメラのみ | 専用ハードウェアが必要 |
| 検出可能な情報 | 2D画像上の関節+相対的なZ座標 | 空間上の絶対的なX/Y/Z座標 |
まとめ
今回の検証では、MediaPipeとUnityを使って、WebカメラのみでUIをジェスチャーで操作する体験を構築し、その有効性を確認しました。
このデモでは、ボタンのクリックやスライダーの調整といったシンプルな操作に焦点を当てましたが、ジェスチャー認識とランドマーク情報を応用することで、さらに幅広いインターフェース設計が可能だと感じました。
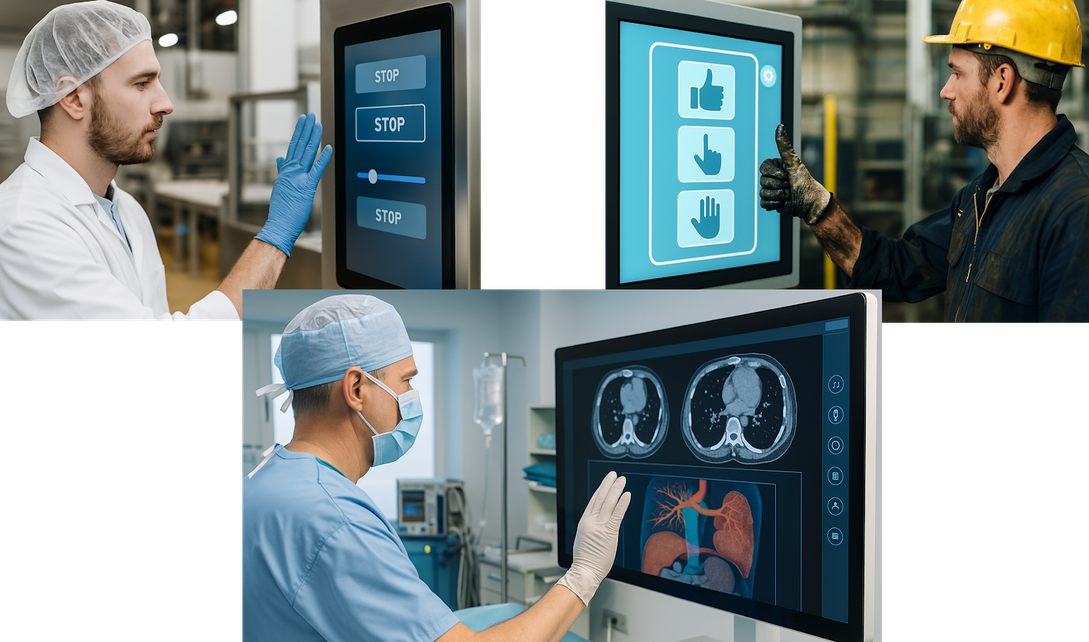
特に、非接触で操作可能なUIは、以下のような場面で大きな価値を持つと考えられます:
- 食品工場など、衛生的に直接触れることが難しい現場
- 医療現場(手術中のUI操作など)
- 工場や整備現場など、手袋や油汚れがある環境
将来的には、XRデバイスや空間UIとの組み合わせによって、直感的かつ自由度の高いインタラクション体験へと発展させていけるのではないでしょうか。

上記ブログの内容に少しでも興味がありましたら、お気軽にご連絡ください。
弊社のエンジニアがフレンドリーに対応させていただきます。
