

テキスト → 3Dモデル
近年、生成AIの技術が進歩しテキストから画像を生成したり、画像から3Dのモデルを生成したりなど、AIモデルにデータを渡すことで少ない情報から大きな出力を得られるようになっています。
弊社ではいままで個々のAIモデルを検証し、利用方法の検討などを行っていました。
StableDiffusionを利用した3Dモデルのデザインプレビュー
Apple Vision Proと生成AI(TripoSR)を使ったアプリ開発
今回はこれらの技術を統合して、テキスト→3Dモデル(リグ付き)を生成し、アニメーションさせる工程を全自動で行うシステムを開発しました。
まずは全体の流れと、最終結果をご覧ください。

「テキストを入力すると3Dモデルが生成され、踊りを行う」といった流れが実現できました。
以下、より詳しくそれぞれの技術仕様を解説します。

テキストからアバターの生成
このシステムでは生成されるモデルを人間型に制限しており、テキストの内容を人間関連以外のものにすると、強制的に人間のような外見のものが生成されることにしています。
主に3つのステップを経て3Dモデルが生成されます。
ステップ1
最初に、テキストからTポーズの2D画像をStable Diffusionで生成します。テキストデータとプロンプトだけではなくOpenPoseの参考スケルトン、マスク、背景、などの画像もオプションの情報として加えています。これはプロンプトを利用するだけでは、作成された画像が「人型の形状+Tポーズ」であることを保証出来ない為、OpenPoseを使用して画像を分析しのデータに補正をかけています。
更に、3DモデルAI生成の画像処理を容易にするために、画像の背景をできるだけシンプルな1色にする必要があるので合わせて調整を行います。
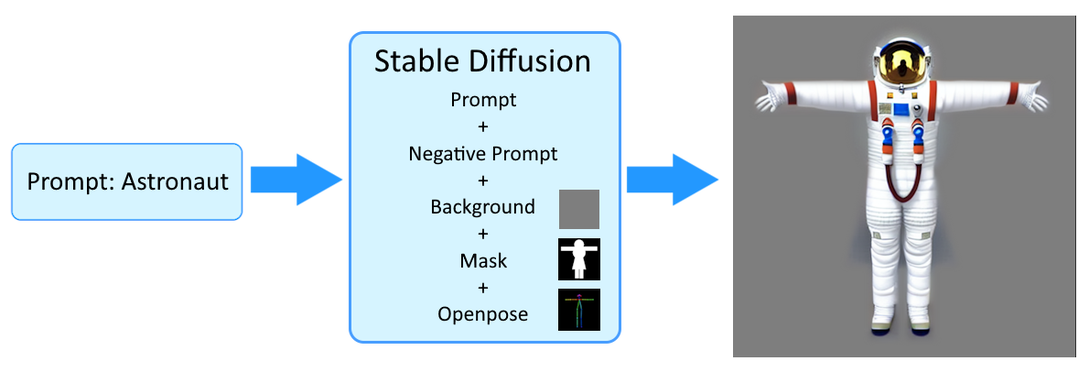
ステップ2
次に、3Dモデル生成AI(Meshy、TripoSR、など)を利用し、ステップ1の画像から3Dモデルを生成します。
結果、3DモデルのOBJファイルとテクスチャのPNGファイルが生成されます。

ステップ3
最後に生成された3Dモデルに従ってリグ付けを自動で行います。

リグ付けに利用した技術に関しては、以下の文章で詳しく説明します。
3Dモデルの自動リグ付け
3Dモデルに自動的にリグを付ける処理はかなり難しく、様々なパターンを検証しました。
まず、「Rignet」というAIモデルがあり、実用性を検証しました。メッシュが人型に寄っていれば良い結果となりましたが、メッシュに頂点の歪みがある場合、NGとなるケースもあり、結果が不安定でした。


他にもいくつか試しましたが、最終的に採用したのはBlenderを使ったアプローチです。
Blenderはモデリング、リギング、アニメーション、シミュレーション、レンダリング、合成、モーショントラッキングなど、3Dパイプライン全体を提供している強力なオープンソースのツールです。今回利用した3Dモデルをリギングする機能では、スケルトン構造(アーマチュア)を作成し、3Dモデルのメッシュとアライメントすることができます。
しかし、Blenderを利用するには1つ大きな問題がありました。Blenderのデフォルトのアーマチュアに人間型のアーマチュアがありますが、3Dモデルのメッシュサイズと向きが異なる場合が多いので合わせる必要があります。生成AIと違って自動的にアーマチュアをメッシュに合わせる機能はないので、今回補正アルゴリズムを独自に開発して対応しました。
脚と腕の位置を検出し、それぞれの部位に対してアーマチュアの位置を調整することで自動的にメッシュに合わせたリグを設定する事ができました。

また補足として、今回作成したシステムではインプットに3Dモデルを直接指定し、自動リグ付けだけを利用することもできるようになっています。TポーズまたはAポーズを行っているモデルであれば対応可能です。


まとめ
今回のブログでは、リアルタイムの自動アバター生成パイプラインを検証し、補正アルゴリズムを含めた開発を紹介しました。
全プロセスが自動で行われるのでアバターの作成時間と労力が削減できます。また、動的に様々な3Dモデルを利用することが出来るので、毎回違ったフィードバックを行うアプリなどを作成することが可能です。ゲーム内でのランダムなキャラクターの生成などにも応用できるかもしれません。
子供向けのアミューズメント施設では自身の動きや回答が反映されて返ってくるとウケが良いので、子供に入力させた内容に合わせたアバターを生成して、AR/VRの空間で一緒に遊べるなどの試作は面白そうです。
次回は弊社で良く利用しているセンサーと組み合わせて、3Dモデルの動き自体もユーザーが自由に作成できるようにしてみたいと思います。

上記ブログの内容に少しでも興味がありましたら、お気軽にご連絡ください。
紹介したアプリをオンライン/オフラインでデモを行うことも可能です。
弊社のエンジニアがフレンドリーに対応させていただきます。
