

最近、何かと話題になる生成AIですが、技術を利用してリアルタイムに3Dモデルのデザインをカスタマイズできるアプリを開発しました。まずは一連の流れを動画でご覧ください。

マイクに変更する部位と色や模様を話しかけると、モデルの衣装や肌色などがリアルタイムに変更されます。
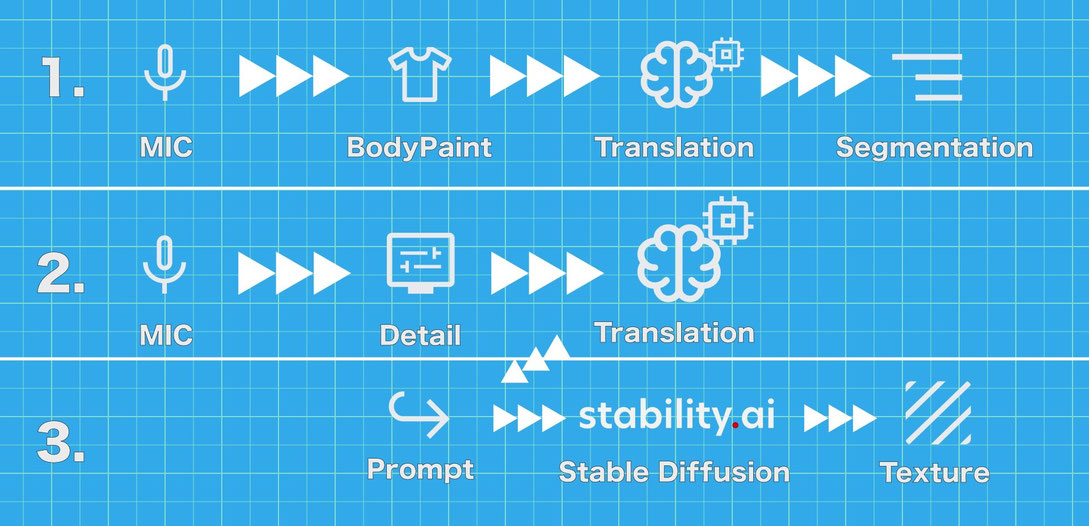
処理の流れとしては以下の様になっています。
1.音声をテキストに変換
2.そのテキストを生成AIに渡して画像を作成
3.画像をテクスチャとしてモデルの指定部位に貼り付け
主に使用した技術は以下の3つです。
- Whisper:ユーザーの音声をテキストに変換するためのAIです。
- Stable Diffusion:ユーザーの指示に基づいて新しいテクスチャーを生成するAIです。
- Unity:生成されたテクスチャーを3Dモデルに適用し、リアルタイムでモデルを表示できる強力なツールです。
今回は音声認識からテクスチャー作成まである程度のスピードが必要という条件があったのでそれを考慮して利用する技術を選びました。WhisperとStable Diffusionにはモデルがいくつかの種類があり、学習データのサイズを下げることで処理スピードを上げることができます。
以下、より詳しくそれぞれの技術仕様と合わせて流れを解説します。

Stable Diffusionを選んだ理由
Stable Diffusionは、入力されたテキストや画像をもとに画像を生成するための強力なAIです。アクセスしやすく使いやすいのはStable Diffusionの重要なポイントです。以下の利点もあります。
- 柔軟性が高い:学習させたモデルを使用することで、アニメのイラストからリアルな人物画まで、幅広い種類の画像を生成することが可能です。
- 無料:無料で枚数無制限の画像生成が行えるので、コストを抑えることができ、気楽に色々なプロジェクトに組み込んだりPoCを作ったりすることができます。
- 活発なコミュニティ:ネット上では豊富なドキュメントと操作方法のチュートリアルが整っています。
Stable Diffusionを使うにはオンライン/ローカルの2種類があります。それぞれ利点がありますが、今回はカスタマイズ性が高いローカルを使ってみることになりました。
ローカルで使う時は公式Githubから入手して実行するのも簡単ですが、Stable Diffusion Web UIというツールの方が拡張機能が整っているので使用感が良いです。Web UIの利点は以下通りです。
- 使いやすいインターフェース:分かり易いUIが用意されているので設定の微調整やプロンプトのテストなどをしやすいです。
- 拡張機能の統合:色々な人気拡張機能がすでに組み込まれていて利便性が高いです。既存画像を修正したりマスクを使ったりする機能も含めて直接UIから操作できるようになっています。
- Web API:APIが用意されているので他のサービスやプロジェクトに導入しやすいです。

アプリの流れ
ステップ1:セグメンテーション
ユーザーの発話を検出しセグメンテーションを行います。
OpenAIの汎用音声認識モデルであるWhisperを利用しました。色々な言語に対応していて翻訳することもできます。
Stable Diffusionは英語のプロンプトのみに対応しているため、日本語で検出されたキーワードを全部英語に翻訳しています。モデルがいくつかあってモデルサイズによって精度と速度がかなり変わってきます。利用できるモデルは以下の通りです。

調査した結果、速度と精度のバランスが一番よかったのは「small」でした。以上のモデルでは日本語の認識精度が英語と比べると少し低いと感じます。
実際利用するとき、Whisperの音声認識を常にONの状態にしました。誤ったコマンドを拾わないようにするために、さらに2つのレイヤーを追加する必要がありました。それらは次の通りです。
部分指定:指定部分のキーワードを検出します。どのキーワードだったかは後から取得できます。

デザイン指定:指定部分を検出したらその後の言葉を生成プロンプトに利用します。

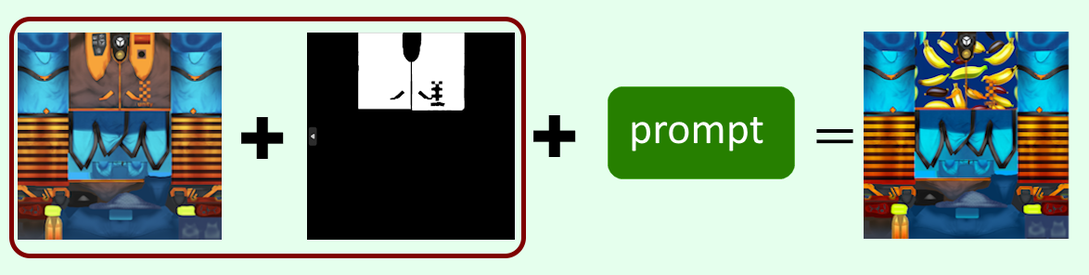
現在の3Dモデルのテクスチャーは、髪、肌、全ての服、ベスト、シャツ、靴下に分かれています。それぞれの部分に対して、似た意味のキーワードも検出できます。ユーザーが発話すると、その中にキーワードが含まれているかどうかを確認し、その部分だけテクスチャーを変更します。そうするには3DモデルのUVマップのどの部分が3Dモデルのどの部分になるかをAIに検出してもらう必要がありますが、Stable Diffusionは現時点でそれができません。対策としてWeb UIのマスク作成機能を利用して各部分のマスクを事前に用意しました。検出された部分のマスクと元UVマップをStable Diffusionに渡すと特定の部分を変更できるようになりました。
ステップ2:プロンプト作成

次のステップで、3Dモデルに適切な結果を生み出すプロンプトを作成します。
これを行うために、AIに何を生成するかを指示する「ベースプロンプト」と、AIに何を生成しないかを指示する「ネガティブプロンプト」のセットを作成する必要があります。これらを作成するために、繰り返しでキーワードをベースプロンプトとネガティブプロンプトに追加したり削除したりして、望む結果が得られるまで続けました。例えば、今回の場合、テクスチャとして画像をフラットにして端まで広げる必要があったため、ユーザーの指示に次のキーワードを追加しました。
“[ユーザーの指示], texture, seamless, flat, 2D”
例:“banana, , texture, seamless, flat, 2D”

これらのキーワードを除くと、次のような画像が生成される可能性があります。
例:“banana”

さらにウォーターマークやホワイトノイズを防ぐために、以下のようなネガティブプロンプトを使用しました。
“ugly, watermark, white noise”
ステップ3:テクチャー作成と張り替え

以上のプロンプト、UVマップ、マスクの他にも枚数や生成する画像にプロンプトをどれだけ強く反映するか(CFGスケール)などの設定がたくさんあります。設定調整を行い、すべてHTTPリクエストでStable Diffusionのサーバーに送信したら画像の配列がbase64形式で返されます。
そこから、そのbase64データを使用してテクスチャを作成し、ユーザーがセグメンテーションのステップで指定した部分のテクスチャファイルを変更すれば完了です!

おわりに
これで、生成AIの実用的な応用の作成プロセスに関する説明は以上となります。
Stable Diffusionは柔軟性が高くて使いやすくてプロンプトがうまく作成できれば色々な場面で活用できそうな強力なツールです。
今回はStable Diffusionにしてみましたが、数々の生成AIモデルの中の1つに過ぎません。これからもさらに多くのモデルを使い、様々な検証を続けていきたいです。
応用例としては3Dスキャンを行った部屋の壁に対して変更を行い、リフォームのシミュレーションに利用したり、AIで直接3Dモデルを生成して、オリジナルのクッションや家具を置いて部屋作りのシミュレーションを行うのも面白そうです。

上記ブログの内容に少しでも興味がありましたら、お気軽にご連絡ください。紹介したアプリをオンライン/オフラインでデモを行うことも可能です。弊社のエンジニアがフレンドリーに対応させていただきます
